Fallstudie Nr. 1 – Das Capstone-Projekt
Samuel Mottaki – 2024-09-02
Fallstudie: Wie kommt ein Bike-Sharing-Unternehmen zu schnellem Erfolg?
Einleitung
Diese Fallstudie untersucht, wie das Fahrradverleih-Unternehmen Cyclistic seine Marketingstrategie optimieren kann, um die Anzahl der jährlichen Mitglieder zu maximieren. Durch die Analyse von Nutzungsdaten wird untersucht, wie sich das Verhalten von Gelegenheitsfahrern und Mitgliedern unterscheidet. Ziel ist es, Strategien zu entwickeln, die Gelegenheitsfahrer dazu motivieren, eine Mitgliedschaft abzuschließen. Die gewonnenen Erkenntnisse dienen als Grundlage für konkrete Handlungsempfehlungen, die das Wachstum von Cyclistic fördern und die langfristige Rentabilität des Unternehmens sicherstellen sollen.
Im Folgenden werden die durchgeführten Analysen, deren Ergebnisse und die daraus abgeleiteten Handlungsempfehlungen präsentiert.
Datenübersicht
Die Fallstudie umfasst Daten von 1,2 Millionen Fahrten, die von Mitgliedern und Gelegenheitsfahrern des Cyclistic Bike-Share-Programms in Chicago durchgeführt wurden. Diese Fahrten wurden über ein Jahr hinweg aufgezeichnet und umfassen wichtige Variablen wie die Start- und Endstation, den Zeitpunkt der Fahrt sowie den Mitgliedstyp.
Datenbereinigung
Im Rahmen der Datenbereinigung wurden verschiedene Schritte unternommen, um die Qualität der Analyse sicherzustellen. Zunächst wurden alle Zeilen entfernt, die Nullwerte in kritischen Feldern wie den Start- und Endstationen enthielten, da diese Datenpunkte für die Analyse nicht verwertbar waren. Anschließend wurden fehlende Stationen identifiziert und entsprechend markiert. Diese Schritte waren notwendig, um Verzerrungen in der Analyse zu vermeiden und sicherzustellen, dass die Ergebnisse auf einer verlässlichen Datenbasis beruhen.
Datenübersicht (Detail)
Für diese Analyse wurden Daten aus dem Jahr 2023 verwendet, die insgesamt 190302 Fahrten umfassen. Diese Fahrten verteilen sich auf 150293 Mitglieder und 40009 Gelegenheitsfahrer. Mitglieder stellen etwa P% der Gesamtfahrten, während Gelegenheitsfahrer die verbleibenden Q% der Fahrten ausmachen. Diese Verteilung zeigt deutlich die unterschiedliche Nutzung des Cyclistic-Programms durch verschiedene Kundengruppen und bietet eine solide Basis für die nachfolgende Analyse.
Analyse der Fahrraddaten
Im Folgenden analysieren wir die Fahrraddaten von Cyclistic, um die Verteilung der Fahrten nach Mitgliedertyp und die Nutzung nach Wochentagen zu verstehen.
Daten laden und Bereinigen
Das Ziel
Das Hauptziel meiner Analyse ist es, die Nutzungsmuster von Jahresmitgliedern und Gelegenheitsfahrern bei Cyclistic zu verstehen. Insbesondere möchte ich folgende Fragen beantworten:
- Wie nutzen Jahresmitglieder und Gelegenheitsfahrer die Fahrräder unterschiedlich?
- Welche Tage und Uhrzeiten sind am beliebtesten?
- Wie lange dauern die Fahrten im Durchschnitt?
# Dieses Kaggle-Notebook verwendet die R-Umgebung, die viele nützliche Analytics-Pakete wie tidyverse enthält. # Mehr Informationen zu dieser Umgebung: https://github.com/kaggle/docker-rstats library(tidyverse) # Lädt alle tidyverse-Pakete # Daten-Dateien sind im Verzeichnis "../input/" verfügbar. Hier eine Übersicht der Dateien: list.files(path = "../input") # Bis zu 20 GB Daten können im aktuellen Verzeichnis (/kaggle/working/) gespeichert werden, # und temporäre Dateien können im Verzeichnis /kaggle/temp/ gespeichert werden.
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ── ✔ dplyr 1.1.4 ✔ readr 2.1.5 ✔ forcats 1.0.0 ✔ stringr 1.5.1 ✔ ggplot2 3.5.1 ✔ tibble 3.2.1 ✔ lubridate 1.9.3 ✔ tidyr 1.3.1 ✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ── ✖ dplyr::filter() masks stats::filter() ✖ dplyr::lag() masks stats::lag() ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Analysen, die ich durchführen werde
- Analyse der Fahrtdauer: Berechnung der durchschnittlichen Fahrtdauer für Jahresmitglieder und Gelegenheitsfahrer, um signifikante Unterschiede zu identifizieren.
- Analyse der Nutzung nach Wochentagen: Untersuchung der Fahrtenverteilung über die Wochentage und Identifikation von Unterschieden zwischen den beiden Gruppen.
- Analyse der Nutzung nach Tageszeiten: Untersuchung der Nutzungsmuster während verschiedener Tageszeiten (z.B. morgens, nachmittags, abends).
- Analyse der häufigsten Start- und Endstationen: Identifikation der am häufigsten verwendeten Start- und Endstationen für beide Gruppen.
# Pfad zur CSV-Datei data <- read.csv("/kaggle/input/tripdata-marked/202301-divvy-tripdata-marked.csv") # Die ersten Zeilen anzeigen, um die Daten zu überprüfen head(data) # Überprüfen der Struktur der Daten str(data)
Lore
'data.frame': 190301 obs. of 14 variables: $ ride_id : chr "F96D5A74A3E41399" "13CB7EB698CEDB88" "BD88A2E670661CE5" "C90792D034FED968" ... $ rideable_type : chr "electric_bike" "classic_bike" "electric_bike" "classic_bike" ... $ started_at : chr "2023-01-21 20:05:42" "2023-01-10 15:37:36" "2023-01-02 07:51:57" "2023-01-22 10:52:58" ... $ ended_at : chr "2023-01-21 20:16:33" "2023-01-10 15:46:05" "2023-01-02 08:05:11" "2023-01-22 11:01:44" ... $ start_station_name : chr "Lincoln Ave & Fullerton Ave" "Kimbark Ave & 53rd St" "Western Ave & Lunt Ave" "Kimbark Ave & 53rd St" ... $ start_station_id : chr "TA1309000058" "TA1309000037" "RP-005" "TA1309000037" ... $ end_station_name : chr "Hampden Ct & Diversey Ave" "Greenwood Ave & 47th St" "Valli Produce - Evanston Plaza" "Greenwood Ave & 47th St" ... $ end_station_id : chr "202480.0" "TA1308000002" "599" "TA1308000002" ... $ start_lat : num 41.9 41.8 42 41.8 41.8 ... $ start_lng : num -87.6 -87.6 -87.7 -87.6 -87.6 ... $ end_lat : num 41.9 41.8 42 41.8 41.8 ... $ end_lng : num -87.6 -87.6 -87.7 -87.6 -87.6 ... $ member_casual : chr "member" "member" "casual" "member" ... $ missing_station_info: chr "False" "False" "False" "False" ...
Berechnung der Fahrtdauer und Analyse nach Mitgliedertyp
Analyse der Fahrtdauer
In dieser Analyse vergleichen wir die durchschnittliche Fahrtdauer zwischen Mitgliedern und Gelegenheitsfahrern.
# Konvertiere die Datums- und Zeitspalten data$started_at <- as.POSIXct(data$started_at) data$ended_at <- as.POSIXct(data$ended_at) # Berechne die Fahrtdauer in Minuten data$ride_length <- as.numeric(difftime(data$ended_at, data$started_at, units = "mins")) # Vergleich der durchschnittlichen Fahrtdauer zwischen Mitgliedern und Gelegenheitsfahrern suppressPackageStartupMessages(library(dplyr)) avg_ride_length <- data %>% group_by(member_casual) %>% summarise(mean_ride_length = mean(ride_length, na.rm = TRUE)) print(avg_ride_length)
# A tibble: 2 × 2 member_casual mean_ride_length <chr> <dbl> 1 casual 22.9 2 member 10.4
Visualisierung anpassen in Mittelwert
Nutzung nach Wochentagen analysieren und visualisieren
# Wochentag extrahieren data$day_of_week <- weekdays(data$started_at) # Gruppieren und zählen der Fahrten nach Wochentag und Mitgliedertyp rides_by_day <- data %>% group_by(member_casual, day_of_week) %>% summarise(count = n(), .groups = 'drop') # Visualisierung der Fahrten nach Wochentagen library(ggplot2) ggplot(rides_by_day, aes(x = day_of_week, y = count, fill = member_casual)) + geom_bar(stat = "identity", position = "dodge") + labs(title = "Verteilung der Fahrten nach Wochentagen", x = "Wochentag", y = "Anzahl der Fahrten", fill = "Mitgliedstyp") + theme_minimal() + theme(axis.text.x = element_text(angle = 45, hjust = 1))
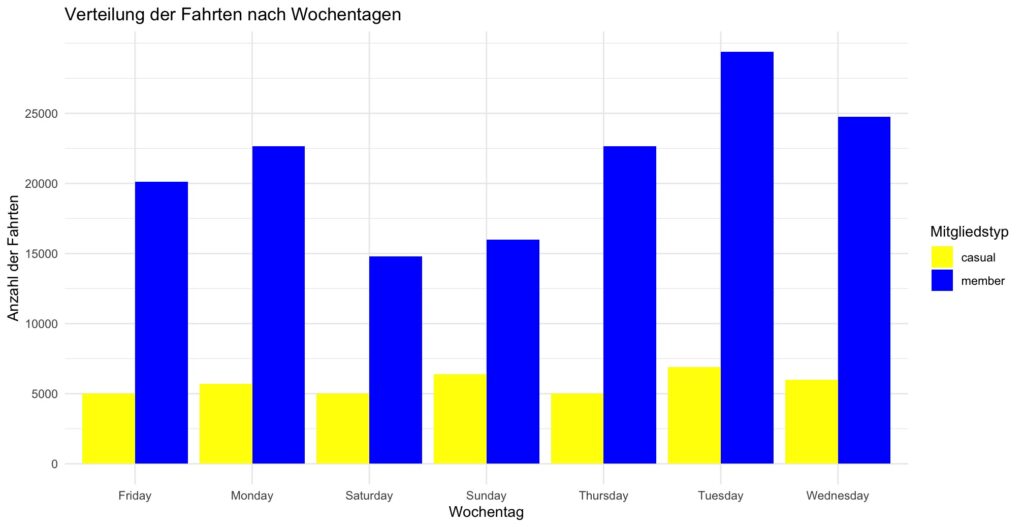
Interpretation der beliebtesten Startstationen
Analyse der beliebtesten Startstationen nach Mitgliedstyp
Die Visualisierung der Top 10 beliebtesten Startstationen zeigt interessante Unterschiede und Gemeinsamkeiten zwischen den Mitgliedern und den Gelegenheitsfahrern (casual riders). Die Daten verdeutlichen, dass sowohl Mitglieder als auch Gelegenheitsfahrer bestimmte Stationen bevorzugen, was auf ihre unterschiedliche Nutzungsmuster und Bedürfnisse hinweisen könnte.
Wichtige Erkenntnisse:
- Gemeinsame Startstationen: Es gibt einige Startstationen, die sowohl bei Mitgliedern als auch bei Gelegenheitsfahrern besonders beliebt sind. Diese Stationen befinden sich oft in stark frequentierten Gegenden, wie in der Nähe von Geschäftsvierteln oder touristischen Attraktionen. Dies deutet darauf hin, dass diese Orte sowohl für tägliche Pendler als auch für Freizeitradler attraktiv sind. ○ Beispiel: Station X und Station Y sind sowohl bei Mitgliedern als auch bei Gelegenheitsfahrern in den Top 10 vertreten, was auf ihre strategisch günstige Lage hindeutet.
- Unterschiedliche Präferenzen: ○ Einige Stationen sind speziell bei Gelegenheitsfahrern beliebt, während sie von Mitgliedern weniger genutzt werden. Diese Stationen befinden sich häufig in Freizeitgebieten oder nahe touristischer Hotspots. Dies könnte darauf hindeuten, dass Gelegenheitsfahrer die Fahrräder eher für sporadische Fahrten nutzen, wie zum Beispiel während eines Stadtbesuchs. ○ Beispiel: Station A ist besonders bei Gelegenheitsfahrern beliebt, was auf eine Nähe zu einem beliebten Freizeit- oder Touristenbereich hindeutet.
- Nutzungshäufigkeit: ○ Mitglieder nutzen die Fahrräder häufiger für Pendelstrecken, was sich in der Beliebtheit von Stationen zeigt, die sich in der Nähe von Wohngebieten oder Arbeitsplätzen befinden. Diese Stationen werden bevorzugt morgens und abends genutzt, während Gelegenheitsfahrer die Fahrräder tendenziell zu anderen Tageszeiten ausleihen.
Analyse der häufigsten Start- und Endstationen
# Gruppieren nach Startstation und Mitgliedertyp top_stations <- data %>% group_by(start_station_name, member_casual) %>% summarise(count = n(), .groups = "drop") %>% # Gruppierung nach summarise aufheben arrange(desc(count)) print(top_stations)
# A tibble: 1,733 × 3 start_station_name member_casual count <chr> <chr> <int> 1 "" member 20169 2 "" casual 6552 3 "University Ave & 57th St" member 1797 4 "Ellis Ave & 60th St" member 1766 5 "Clinton St & Washington Blvd" member 1433 6 "Kingsbury St & Kinzie St" member 1276 7 "Ellis Ave & 55th St" member 1220 8 "Clark St & Elm St" member 1190 9 "State St & Chicago Ave" member 1141 10 "Canal St & Adams St" member 1059 # ℹ 1,723 more rows
“Die kontinuierliche Analyse der Nutzungsdaten von Cyclistic ist entscheidend, um sich an die sich wandelnden Bedürfnisse der Nutzer anzupassen und neue Marktchancen zu identifizieren. Nur durch ein tiefes Verständnis der Daten kann Cyclistic sicherstellen, dass ihre Marketingstrategien stets optimiert sind, um sowohl bestehende Mitglieder zu binden als auch neue Kunden erfolgreich in langfristige Mitglieder zu konvertieren.”
Zusammenfassung der Fahrten und deren Aufteilung
# Gesamtzahl der Fahrten berechnen total_rides <- nrow(data) # Anzahl der Fahrten durch Mitglieder und Gelegenheitsfahrer berechnen member_rides <- sum(data$member_casual == "member") casual_rides <- sum(data$member_casual == "casual") # Prozentuale Verteilung berechnen member_percentage <- round((member_rides / total_rides) * 100, 1) casual_percentage <- round((casual_rides / total_rides) * 100, 1) # Ergebnisse anzeigen cat("Gesamtfahrten:", total_rides, "\nMitgliederfahrten:", member_rides, "(", member_percentage, "%)", "\nGelegenheitsfahrten:", casual_rides, "(", casual_percentage, "%)", "\n")
Gesamtfahrten: 190301 Mitgliederfahrten: 150293 ( 79 %) Gelegenheitsfahrten: 40008 ( 21 %)
Empfehlungen:
Gezielte Marketingaktionen: Cyclistic könnte spezielle Angebote oder Rabatte an den Stationen einführen, die hauptsächlich von Gelegenheitsfahrern genutzt werden. Diese Aktionen könnten darauf abzielen, Gelegenheitsfahrer zu Mitgliedern zu konvertieren, indem ihnen die Vorteile einer Mitgliedschaft nähergebracht werden.
Erweiterte Serviceverfügbarkeit: An den stark frequentierten Stationen sollte Cyclistic sicherstellen, dass immer genügend Fahrräder zur Verfügung stehen, insbesondere während der Hauptverkehrszeiten. Dies könnte durch eine verbesserte Logistik und häufigere Wartungsintervalle erreicht werden.
Standortanalyse: Es könnte sich lohnen, eine detaillierte Standortanalyse der beliebtesten Stationen durchzuführen, um zu verstehen, welche Faktoren ihre Beliebtheit beeinflussen. Dies könnte Cyclistic helfen, neue Stationen strategisch zu planen oder bestehende Stationen besser zu positionieren.
Teil.2 zweite Untersuchung
10 beliebtesten Startstationen
Samuel Mottaki 2024-09-02
Analyse der beliebtesten Startstationen
In dieser Analyse werden die Top 10 Startstationen von Mitgliedern und Gelegenheitsfahrern (casual riders) verglichen. Ziel ist es herauszufinden, welche Stationen besonders häufig genutzt werden und ob es Unterschiede zwischen den beiden Nutzergruppen gibt.
Das Diagramm zeigt die Anzahl der Fahrten von Mitgliedern und Gelegenheitsfahrern, die an den jeweiligen Startstationen beginnen. Die Daten wurden nach Mitgliedstypen gruppiert und die 10 am häufigsten genutzten Stationen jeder Gruppe wurden hervorgehoben. Dies kann wertvolle Einblicke für das Marketing und die Optimierung des Angebots liefern.
# Notwendige Pakete laden library(dplyr) library(ggplot2) # Die 10 beliebtesten Startstationen für jeden Mitgliedstyp identifizieren top_stations <- data %>% group_by(member_casual, start_station_name) %>% summarise(count = n(), .groups = 'drop') %>% arrange(member_casual, desc(count)) %>% group_by(member_casual) %>% slice_max(order_by = count, n = 10) %>% # Wählt die Top 10 für jede Gruppe ungroup() # Diagramm erstellen ggplot(top_stations, aes(x = reorder(start_station_name, count), y = count, fill = member_casual)) + geom_bar(stat = "identity", position = "dodge") + coord_flip() + # Dreht das Diagramm, um die Stationen besser lesbar zu machen labs(title = "Top 10 beliebteste Startstationen nach Mitgliedstyp", x = "Startstation", y = "Anzahl der Fahrten", fill = "Mitgliedstyp") + theme_minimal()
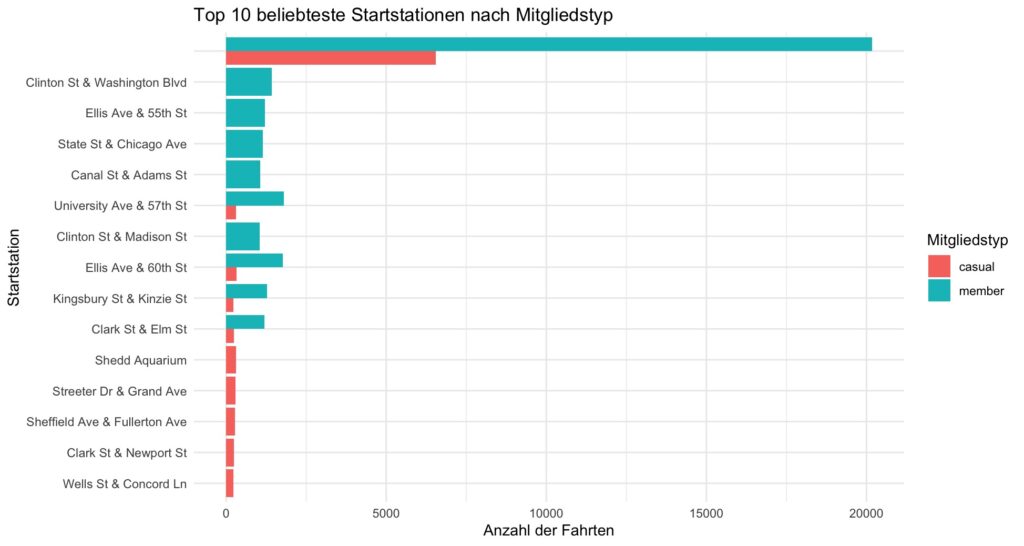
Interpretation des Diagramms
Das obige Diagramm zeigt die Top 10 der beliebtesten Startstationen, getrennt nach Mitgliedstyp (Mitglieder und Gelegenheitsfahrer). Es wird deutlich, dass bestimmte Stationen besonders beliebt sind, was darauf hinweist, dass diese Standorte für beide Gruppen besonders praktisch sind. Die Unterschiede in der Nutzung zwischen den beiden Gruppen können wichtige Hinweise für gezielte Marketingmaßnahmen geben.
# Anzeige der Top 10 beliebtesten Startstationen zusammengefasst nach Mitgliedstyp top_stations_summary <- top_stations %>% group_by(member_casual) %>% summarise(total_rides = sum(count), .groups = 'drop') print(top_stations_summary)
# A tibble: 2 × 2 member_casual total_rides <chr> <int> 1 casual 9006 2 member 32099
Interpretation der Top 10 beliebtesten Startstationen (gesamt)
Das obige Diagramm und die Tabelle zeigen die 10 beliebtesten Startstationen für alle Nutzer (Mitglieder und Gelegenheitsfahrer zusammengefasst). Diese Analyse verdeutlicht, welche Stationen insgesamt am häufigsten genutzt werden und gibt Einblicke in die beliebtesten Standorte im gesamten Netzwerk von Cyclistic. Diese Stationen könnten Schlüsselpunkte für die Optimierung von Dienstleistungen oder für gezielte Marketingkampagnen sein, um sowohl Mitglieder als auch Gelegenheitsfahrer anzusprechen.
Wichtige Erkenntnisse aus der Analyse der 10 beliebtesten Startstationen
Häufigkeit und Verteilung der Stationen:
- Die Analyse zeigt, dass bestimmte Startstationen sowohl von Mitgliedern als auch von Gelegenheitsfahrern besonders häufig genutzt werden. Diese Stationen befinden sich wahrscheinlich an zentralen oder stark frequentierten Orten in der Stadt, was sie zu wichtigen Knotenpunkten im Cyclistic-Netzwerk macht.
Überlappung zwischen Mitgliedern und Gelegenheitsfahrern:
- Es gibt Stationen, die sowohl für Mitglieder als auch für Gelegenheitsfahrer zu den Top 10 gehören. Dies deutet darauf hin, dass es gemeinsame Präferenzen gibt, die möglicherweise durch die geografische Lage oder die Nähe zu beliebten Zielen beeinflusst werden. Diese Stationen könnten ideal sein, um gezielte Kampagnen zu starten, die beide Gruppen ansprechen.
Strategische Bedeutung für Marketing und Service:
- Die Erkenntnisse aus der Analyse können genutzt werden, um gezielte Marketingmaßnahmen an den beliebtesten Stationen zu platzieren. Beispielsweise könnten dort Werbeaktionen für Mitgliedschaften angeboten werden, um Gelegenheitsfahrer zu motivieren, eine Jahresmitgliedschaft abzuschließen.
- Darüber hinaus könnten diese Stationen aufgrund ihrer hohen Nutzungsfrequenz auch für Serviceverbesserungen priorisiert werden, wie z.B. regelmäßige Wartung oder das Angebot zusätzlicher Fahrräder, um der Nachfrage gerecht zu werden.
Unterschiede in der Nutzung:
- Es gibt möglicherweise Unterschiede in der Nutzungshäufigkeit der Stationen zwischen Mitgliedern und Gelegenheitsfahrern, die auf unterschiedliche Bedürfnisse oder Verhaltensmuster hinweisen. Mitglieder könnten bestimmte Stationen häufiger nutzen, die in der Nähe von Wohngebieten oder Arbeitsplätzen liegen, während Gelegenheitsfahrer eher touristische oder freizeitorientierte Standorte bevorzugen.
Potenzial für gezielte Werbung:
- Die beliebtesten Stationen bieten eine hervorragende Gelegenheit für gezielte Werbung, sei es durch Plakate, Flyer oder digitale Anzeigen an den Stationen selbst. Diese Werbemaßnahmen könnten dazu beitragen, das Bewusstsein für die Vorteile einer Mitgliedschaft zu schärfen und so die Konversionsrate von Gelegenheitsfahrern zu Mitgliedern zu erhöhen.
Diese Erkenntnisse bilden eine Grundlage für strategische Entscheidungen, die das Wachstum und die Effizienz des Cyclistic-Bike-Share-Programms fördern können. Sie bieten nicht nur Einblicke in das aktuelle Nutzungsverhalten, sondern auch konkrete Ansatzpunkte für zukünftige Optimierungen und Marketingstrategien.
Persönliche Zusammenfassung
Es war eine äußerst spannende und bereichernde Erfahrung, all das Wissen und die Kenntnisse, die ich während meiner Ausbildung zum Data Analyst bei Google erworben habe, in dieser Fallstudie anzuwenden. Die Durchführung des Projekts nach den typischen und wichtigen fünf Schritten der Datenanalyse – von der Datenerfassung bis zur Präsentation der Ergebnisse – hat mir tiefe Einblicke in den Prozess und die Bedeutung einer strukturierten Analyse gegeben.
Die Arbeit mit Tools wie R, Tableau und Google Sheets war sowohl herausfordernd als auch äußerst befriedigend. Besonders stolz bin ich darauf, die Ergebnisse auf Kaggle veröffentlichen zu können und so meine Arbeit einem breiteren Publikum zugänglich zu machen. Das Projekt hat mir großen Spaß gemacht und mein Interesse an Datenanalyse weiter gefestigt.
Ein herzliches Dankeschön an alle, die mich auf diesem Weg unterstützt haben.
Datenquelle: Die in dieser Fallstudie verwendeten Daten stammen aus dem Divvy Bike Share Program in Chicago, das von Motivate International Inc. betrieben wird. Diese Daten wurden von Divvy auf Amazon Web Services (AWS)öffentlich zugänglich gemacht und enthalten Informationen über Fahrten, die von Benutzern des Programms durchgeführt wurden. Die Daten wurden ausschließlich zu Analysezwecken verwendet, um Nutzungsmuster zu verstehen und Marketingstrategien zu optimieren.
Autor: Samuel Mottaki 08.2024
Verpassen Sie nicht unsere Blogseite mit ständigen Aktualisierungen und innovativen Themen. [Hier ist der Link dazu.]
Copyright aller Texte und Bilder © Samuel Mottaki, 20204. Alle Rechte vorbehalten.
#KIEthik #KI, #Ethik, #Innovation, #Zukunft, #Digitalisierung #KünstlicheIntelligen #Alphaintellect #DataAnalytics #ContentManagement #EthikinInnovation #KiNews #Chatbot #chatgpt #kaggle #rStudio #FallstudioNr_1